
تفاوت هوش مصنوعی و یادگیری ماشین در چیست؟ چه چیزی یادگیری ماشین و یادگیری عمیق را از یکدیگر متمایز میکند؟
هوش مصنوعی، یادگیری ماشین، یادگیری عمیق و شبکههای عصبی، اصطلاحاتی هستند که اغلب به جای یکدیگر مورد استفاده قرار میگیرند اما چه تفاوتهایی باعث شده که هر یک از آنها را یک فناوری منحصربهفرد بدانیم؟
فناوری هر روز بیشتر از قبل با زندگی روزمره انسانها عجین میشود و شرکتها برای همگامی با انتظارات متغیر مصرفکنندگان و با هدف تسهیل فرایندها، به الگوریتمهای یادگیری اعتماد میکنند. همین حالا هم میتوانیم کاربرد این الگوریتمها را در شبکههای اجتماعی (مثل تشخیص اشیا در عکسها) یا مکالمه مستقیم با دستگاهها از طریق دستیارهای صوتی مانند Siri یا Cortana مشاهده کنیم.
این فناوریها معمولاً با هوش مصنوعی، یادگیری ماشین، یادگیری عمیق و شبکههای عصبی ارتباط دارند. با وجود اینکه این چهار عنصر، هر یک نقش خاصی را ایفا میکنند اما در بسیاری اوقات، اشتباهاً به جای یکدیگر به کار میروند و این امر میتواند به ایجاد سردرگمی درباره تفاوتهای ظریف بین آنها منجر شود. امیدواریم آنچه در ادامه تقدیمتان میشود، بتواند بخش زیادی از ابهامات پیرامون این موضوع را رفع نموده و بهطور خاص، تفاوت هوش مصنوعی و یادگیری ماشین را برایتان بهخوبی توضیح دهد.
ارتباط بین هوش مصنوعی، یادگیری ماشین، یادگیری عمیق و شبکههای عصبی
عروسکهای جالب و تودرتوی روسی که به آنها ماتروشکا میگویند، میتوانند مثال ساده و خوبی برای درک تفاوت هوش مصنوعی و یادگیری ماشین و نیز تفاوت آن با شبکههای عصبی و یادگیری عمیق باشند. همانطور که در شکل ملاحظه میکنید، هر قطعه عروسک، درواقع جزئی از قطعه قبل است.
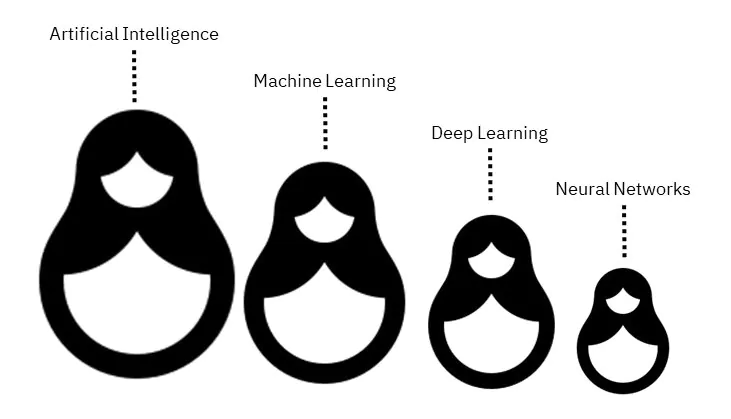
با در نظر گرفتن این مثال بهوضوح میتوان دید که 1) یادگیری ماشین، زیرمجموعه هوش مصنوعی، 2) یادگیری عمیق، زیرمجموعه یادگیری ماشین و 3) شبکه عصبی، ستون اصلی الگوریتمهای یادگیری عمیق است. درواقع آنچه یک شبکه عصبی را از الگوریتمهای یادگیری عمیق متمایز میکند، تعداد لایههای گره یا عمق شبکه است که اگر بیشتر از 3 باشد، به آن یادگیری عمیق میگوییم.
شبکه عصبی چیست؟
برای درک تفاوت هوش مصنوعی و یادگیری ماشین، بگذارید از پایین به بالا شروع کنیم؛ یعنی ابتدا به کوچکترین قطعه از ماتروشکا بپردازیم. شبکههای عصبی (Neural Networks) یا شبکههای عصبی مصنوعی (ANN)، سیستمهای محاسباتی هستند که بهواسطه مجموعهای از الگوریتمها از سازوکار مغز انسان تقلید میکنند. هر شبکه عصبی در پایهایترین سطح، از چهار مؤلفه تشکیل شده است: ورودیها، وزنها، آستانه (threshold) یا بایاس و نهایتاً خروجی.
اگر بخواهیم رابطه بین این مؤلفهها را با یک فرمول جبری نشان دهیم، به چنین رابطهای میرسیم که به یک معادله رگرسیون خطی شباهت دارد:
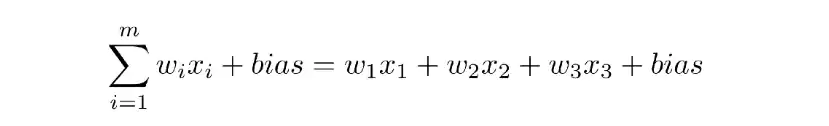
بگذارید برای روشن شدن موضوع، یک مثال ملموستر بزنیم. فرض کنیم میخواهیم ببینیم که آیا شما باید برای شام، پیتزا سفارش دهید یا نه؟ پاسخ این سؤال، همان نتیجه الگوریتم یا y-hat است. باز هم فرض میکنیم که سه عامل در تصمیمگیری شما نقش دارند:
- آیا با سفارش دادن پیتزا، در وقتتان صرفهجویی میکنید؟ (Yes:1, No: 0)
- آیا با سفارش دادن پیتزا، وزن کم میکنید؟ (Yes:1, No: 0)
- آیا با سفارش دادن پیتزا، از نظر اقتصادی، صرفهجویی میکنید؟ (Yes:1, No: 0)
توجه کنید که X=1 متناظر با پاسخ “بله” برای هر سؤال و X=0 متناظر با پاسخ “خیر” برای پرسشهای فوق است.
حالا فرض کنید ورودیهای زیر را داشته باشیم:
- X1= 1، چون شما برای تهیه شام، زمانی صرف نمیکنید.
- X2= 0، چون شما یک غذای پرکالری میخورید.
- X3=1، چون فقط یک مینیپیتزا سفارش میدهید.
برای اینکه قضیه ساده باشد، در اینجا ورودیهای ما فقط مقادیر باینری 0 و 1 را اختیار میکنند. البته توجه داشته باشید که شبکههای عصبی، اساساً از نورونهای سیگموئید که میتوانند مقادیری از منفی بینهایت تا مثبت بینهایت بگیرند، استفاده میکنند. درک این تمایز از آن جهت مهم است که اکثر مسائل در دنیای واقعی، از نوع غیرخطی هستند؛ بنابراین ما به مقادیری نیاز داریم که میزان تأثیر هر ورودی تکی را روی نتیجه یا خروجی، کاهش داده یا تعدیل کند. بااینحال، مفروضات ما در این مثال و استفاده از مقادیر باینری، کمک میکند تا مبانی ریاضیاتی الگوریتم را بهتر درک کنیم.
حالا نوبت به وزن دهی ورودیهای تکی میرسد. وزن بیشتر هر ورودی تکی، نشان میدهد که آن ورودی، در مقایسه با ورودیهای دیگر، سهم بیشتری در خروجی دارد.
فرض کنید زمان بیشتر از تناسباندام و تناسباندام بیشتر از پول برایتان اهمیت داشته باشد. پس به ورودی، به ترتیب مقادیر 5، 3 و 2 را اختصاص میدهیم. بهعبارتدیگر:
W1=5 W2=3 W3=2
سرانجام ما مقدار یا ارزش آستانهای را 5 فرض میکنیم که به مقدار انحراف یا بایاس -5 تبدیل میشود. حالا که همه مقادیر لازم را داریم، میتوانیم آنها را در فرمول جایگذاری کنیم.
بگذارید هر آنچه را تا اینجا گفتیم، خلاصه کنیم:
Y-hat (نتیجه پیشبینیشده) = خریدن یا نخریدن پیتزا
Y-hat = (1*5) + (0*3) + (1*2) – 5
Y-hat = 5 + 0 + 2 – 5
میبینیم که Y=2 شده که این مقدار بزرگتر از صفر است.
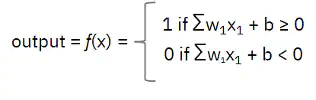
ازآنجاییکه Y-hat برابر با 2 شده، خروجی تابع فعالسازی، برابر 1 خواهد بود و این بدان معناست که ما پیتزا سفارش خواهیم داد. البته یک شکمو از هر الگوریتمی که استفاده کند، باز هم به این نتیجه میرسد که باید پیتزا بخرد!
اگر خروجی هر گره تکی بیشتر از مقدار آستانه باشد، آن گره فعال میشود و دادهها را به لایه بعدی شبکه میفرستد. در غیر این صورت، هیچ دادهای به لایه بعد منتقل نمیشود. حالا تصور کنید که فرایند فوق، چند بار برای یک تصمیم واحد، تکرار شود زیرا شبکههای عصبی بهعنوان بخشی از الگوریتمهای یادگیری عمیق، چندین لایه پنهان دارند. هر لایه پنهان، تابع فعالسازی خاص خودش را دارد و بهطور بالقوه، اطلاعات مربوط به لایه قبل را به لایه بعد منتقل میکند. وقتی همه خروجیهای لایههای پنهان ایجاد شوند، از این خروجیها بهعنوان ورودی برای محاسبه خروجی نهایی شبکه عصبی استفاده میشود.
تأثیر تغییر وزن، تفاوت اصلی شبکههای عصبی با رگرسیون است. ما در رگرسیون میتوانیم یک وزن را بدون آنکه روی ورودیهای دیگر یک تابع، تأثیر بگذارد، تغییر دهیم اما این کار در شبکههای عصبی امکانپذیر نیست. ازآنجاییکه خروجی یک لایه به لایه بعد منتقل میشود، هر تغییری میتواند روی نورونهای دیگر شبکه، اثر آبشاری داشته باشد.
یادگیری عمیق چه تفاوتی با شبکههای عصبی دارد؟
برای نزدیکتر شدن به تفاوت هوش مصنوعی و یادگیری ماشین، حالا باید ببینیم که یادگیری عمیق چه فرقی با شبکههای عصبی دارد؟ هرچند این تفاوت بهطور ضمنی در بخش قبل، توضیح داده شد اما بهتر است آن را به شکلی دقیقتر مورد بررسی قرار دهیم. واژه “عمیق” در یادگیری عمیق (Deep Learning)، به عمق لایهها در یک شبکه عصبی اشاره دارد. یک شبکه عصبی را که بیش از سه لایه (شامل ورودیها و خروجی) داشته باشد، میتوانیم یک الگوریتم یادگیری عمیق بدانیم. این مفهوم در شکل زیر نشان داده شده است:
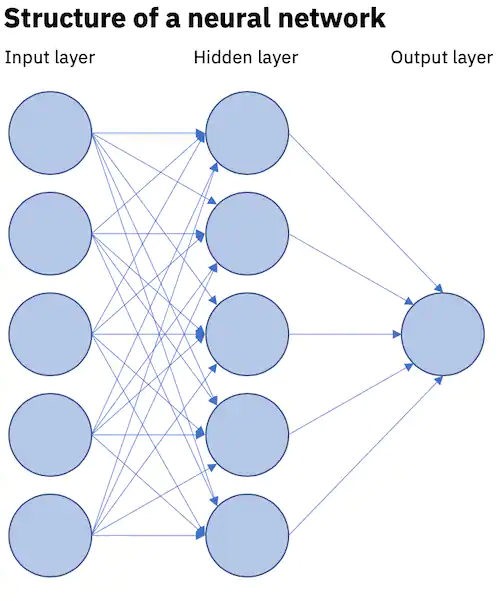
اکثر شبکههای عصبی عمیق، از نوع Feed-Forward یا پیشخور هستند؛ به این معنا که تنها در یک مسیر، از ورودی به سمت خروجی، حرکت میکنند. بااینحال شما میتوانید روش پس انتشار (back-propagation) را به مدلتان آموزش دهید تا بتواند در جهت مخالف، یعنی از خروجی به سمت ورودی حرکت کند. بهاینترتیب میتوانیم با محاسبه و انتساب خطای مربوط به هر نورون، الگوریتم را به شکلی مناسب، تنظیم و برازش کنیم.
یادگیری عمیق چه تفاوتی با یادگیری ماشین دارد؟
دانستیم که یادگیری عمیق، زیرمجموعهای از یادگیری ماشین (Machine Learning) است و آنچه تفاوت بین این دو را رقم میزند، نحوه یادگیری الگوریتم در هر یک از آنهاست.
یادگیری ماشین کلاسیک یا غیرعمیق، برای یادگیری به مداخله انسان وابسته بوده و برای درک تفاوتهای بین دادههای ورودی، به برچسبگذاری نیاز دارد. بهعنوانمثال اگر بخواهید یک منوی تصویری شامل سه نوع فستفود را به کسی نشان دهید، عکس هر غذای فوری را با نام آن مثلاً پیتزا، همبرگر، تاکو و … برچسبگذاری میکنید. مدل یادگیری ماشین هم بر اساس دادههای برچسبگذاری شده، یاد میگیرد که به این نوع یادگیری، یادگیری تحت نظارت میگویند.
یادگیری ماشین عمیق، با وجود اینکه میتواند از دادههای برچسبگذاری شده در راستای آموزش الگوریتمش استفاده کند، اما لزوماً به برچسبگذاری دادهها نیازی ندارد. این مدل میتواند از یادگیری بدون نظارت برای آموزش خودش استفاده کند. درواقع توانایی کار کردن با دادههای بدون ساختار یا بدون برچسب، تفاوت اصلی یادگیری بدون نظارت با یادگیری تحت نظارت است.
مدل یادگیری ماشین از طریق مشاهده الگوهای موجود در دادهها و شناسایی آنها میتواند دادههای ورودی را خوشهبندی و طبقهبندی کند. اگر همان مثال فستفود را در نظر بگیریم، میتوان تصاویر پیتزاها، همبرگرها و تاکوها را بر اساس شباهتهایی که با یکدیگر دارند، در سه دسته، طبقهبندی کرد. با این توضیحات، برای بهبود دقت یک مدل یادگیری عمیق باید آن را با دادههای بیشتری (که به برچسبگذاری نیازی ندارند) تغذیه کنیم؛ درحالیکه یک مدل یادگیری ماشین با توجه به ساختار دادههای اصلی، به دادههای کمتری (البته برچسبگذاری) نیاز دارد. از یادگیری عمیق در وهله اول برای استفاده در امور پیچیدهتری مثل دستیارهای مجازی، کشف تقلب و … استفاده میشود.
تفاوت هوش مصنوعی و یادگیری ماشین
سرانجام به تفاوت هوش مصنوعی (Artificial Intelligence) و یادگیری ماشین میرسیم. هوش مصنوعی، واژهای است که برای طبقهبندی ماشینهایی که از سازوکار هوش انسان تقلید میکنند، بیشترین کاربرد را دارد. از هوش مصنوعی در اموری مثل پیشبینی، اتوماسیون، ترجمه و بهینهسازی طیف گستردهای از کارها، استفاده میشود.
بهطورکلی، هوش مصنوعی در سه گروه اصلی طبقهبندی میشود:
- هوش مصنوعی محدود (ANI)
- هوش مصنوعی جامع (AGI)
- سوپرهوش یا اَبَرهوش مصنوعی (ASI)
هوش مصنوعی محدود را در دسته هوش ضعیف و دو نوع دیگر را در دسته هوش قوی قرار میدهند. هوش ضعیف به نوعی از هوش مصنوعی میگویند که صرفاً در انجام یک کار یا وظیفه بسیار خاص مثل برنده شدن در یک بازی شطرنج یا شناسایی چهره یک فرد در بین تصاویر موجود در یک آلبوم توانمند است. هر چه به سمت مدلهای قدرتمندتر هوش مصنوعی مثل AGI و ASI حرکت میکنیم، با تلفیق جنبههای بیشتری از توانمندیهای انسانی مثل تفسیر لحن یا درک احساسات روبرو میشویم. چت باتها و دستیارهای صوتی مجازی مثل Siri و Cortana توانستهاند تا حدی در این زمینهها پیشرفت کنند اما هنوز آنقدر توانمند نشدهاند که بتوانیم آنها را نوعی هوش مصنوعی قوی بدانیم. به همین دلیل کماکان در گروه ANI یا هوش مصنوعی ضعیف طبقهبندی میشوند.
هوش مصنوعی قوی از طریق مقایسه تواناییاش با توانایی انسان تعریف میشود. هوش مصنوعی جامع، عملکردی همتراز با یک انسان دارد و سوپر هوش مصنوعی که به آن اَبَرهوش هم میگویند، از هوش و توانمندی انسانی هم جلو میزند. با وجود اینکه فاصله زیادی تا ساخت هوش مصنوعی قوی وجود دارد اما این حوزه بهسرعت در حال پیشرفت است. شخصیت Dolores در سریال آمریکایی Westworld، مثالی از یک هوش مصنوعی قدرتمند است.
چالشهای استفاده از هوش مصنوعی
شناخت تفاوت هوش مصنوعی و یادگیری ماشین، پایان کار نیست. با وجود اینکه هر چهار مفهومی که در حوزه هوش مصنوعی وجود دارند، به تسهیل فرایندهای کسبوکار و بهبود تجربه مشتریان کمک میکنند، اما تحقق اهداف استفاده از آنها، میتواند بهخودیخود، یک چالش دشوار باشد. قبل از هر چیز، شما باید از بابت داشتن سیستمهای مناسبی که بتوانند برای ایجاد الگوریتمهای یادگیری، دادهها را بهخوبی مدیریت کنند، اطمینان حاصل کنید. فراموش نکنید که مدیریت داده، از ساخت مدلهای مبتنی بر هوش مصنوعی، بهمراتب دشوارتر است. شما به مکانی برای ذخیره دادهها و همینطور پالایش و کنترل آنها برای رفع سوگیریهای احتمالی نیاز دارید.
سخن آخر
تفاوت هوش مصنوعی و یادگیری ماشین، سؤال مشترک بسیاری از علاقهمندان به این حوزههاست و ما تلاش کردیم در این مطلب از وبلاگ واکافت، حتیالامکان پاسخ روشنی به این سؤال بدهیم. بااینحال، دامنه سؤالات، صرفاً به تفاوت هوش مصنوعی و یادگیری ماشین محدود نیست. یادگیری عمیق و شبکههای عصبی، از دیگر مفاهیم مهم و مرتبط با هوش مصنوعی هستند که پیرامون آنها نیز سؤالات زیادی مطرح میشود. به همین دلیل در این مطلب، ضمن معرفی بیشتر این دو مفهوم، به ارائه توضیحاتی درباره تفاوت هوش مصنوعی و یادگیری عمیق پرداختیم.
هوش مصنوعی، یادگیری ماشین، یادگیری عمیق و شبکههای عصبی، چهار مفهوم مرتبط و تودرتو هستند که در عین وابستگی، با یکدیگر تفاوت دارند. به همین سبب، شایسته است که ضمن آشنایی با مفهوم هر یک از آنها، استفاده درستی از این عبارات داشته باشیم. همانطور که دیدیم با شناخت اجزای کوچکتر عروسک ماتروشکا، درک تفاوت هوش مصنوعی و یادگیری ماشین کار چندان سختی نبود.
منابع:
https://www.ibm.com/cloud/blog/ai-vs-machine-learning-vs-deep-learning-vs-neural-networks