
مدلهای یادگیری ماشین یا همان مدلهای ماشین لرنینگ، این روزها در زمینههای تصمیمگیری و پیشبینی، سروصدای زیادی به پا کردهاند. احتمالاً شما هم اخیراً عبارت “یادگیری ماشین” را زیاد شنیدهاید و شاید بارها از خودتان این سؤال را پرسیده باشید که Machine Learning چیست؟
در این مطلب از واکافت، میخواهیم ضمن پاسخ به سؤال فوق، با بیانی ساده، به معرفی انواع مدلهای یادگیری ماشین پرداخته و اطلاعات مفید و جالبی را درباره آنها خدمتتان ارائه دهیم. از شما خوبان دعوت میکنیم تا انتها ما را همراهی کنید.
یادگیری ماشین چیست؟
وقتی دادههای زیادی را در یک برنامه کامپیوتری بارگذاری کنیم و با انتخاب مدلی برای برازش دادهها، امکان پیشبینی نتایج را بدون کمک و دخالت عامل انسانی برای کامپیوتر فراهم سازیم، یادگیری ماشین تحقق میپذیرد. کامپیوترها با استفاده از الگوریتمها، مدلهای یادگیری ماشین را ایجاد میکنند که این مدلها میتوانند یک معادله ساده (مثلاً معادله یک خط) یا یک سیستم بسیار پیچیده از ریاضیات و منطق باشند که به کامپیوتر اجازه میدهند بهترین پیشبینیها را داشته باشد.
انتخاب عبارت یادگیری ماشین، انتخابی بهجا و درست است زیرا وقتی شما مدلی را برای تنظیم کردن و استفاده انتخاب میکنید، کامپیوتر نیز برای یادگیری الگوهای موجود در دادههایی که وارد آن کردهاید، از همین مدل استفاده میکند. بهاینترتیب، شما میتوانید شرایط یا مشاهدات جدید را وارد کامپیوتر کنید و کامپیوتر نیز نتایج حاصل از آنها را پیشبینی کند.
یادگیری ماشین تحت نظارت
یادگیری تحت نظارت، نوعی یادگیری ماشینی بوده که در آن، دادههای ورودی به مدل، برچسبگذاری میشوند؛ یعنی نتیجه مشاهده (مثلاً ردیف دادهها) مشخص است. بهعنوانمثال، اگر مدلی برای پیشبینی رفتن یا نرفتن دوستانتان به استادیوم برای تماشای مسابقه فوتبال ایجاد کنید، ممکن است متغیرهایی را مثل دما، روز هفته و … داشته باشید. اگر این دادهها دارای تگ یا برچسب باشند، آنگاه به متغیری نیاز دارید که در صورت رفتن دوستانتان به استادیوم مقدار 1 و در غیر این صورت، مقدار 0 را اختیار کند.
یادگیری ماشین بدون نظارت
همانگونه که احتمالاً خودتان هم حدس زدهاید، یادگیری ماشین بدون نظارت، نقطه مقابل یادگیری تحت نظارت است و فرق آن، عدم برچسبگذاری دادههاست. در این نوع یادگیری، شما حتی نمیدانید که آیا دوستانتان به استادیوم رفتهاند یا نه؟ بلکه این به کامپیوتر بستگی دارد تا با استفاده از یک مدل، الگویی پیدا کند و بر مبنای الگو، آنچه را اتفاق افتاده حدس بزند یا آنچه را رخ خواهد داد، پیشبینی کند. بهعبارتدیگر، در مدلهای یادگیری ماشین بدون نظارت، کامپیوتر بدون دخالت ما و بهطور خودکار، به الگو و ارتباط بین دادهها پی میبرد.
مدلهای یادگیری ماشین تحت نظارت
1. رگرسیون لجستیک
معرفی مدلهای یادگیری ماشین را با مدل رگرسیون لجستیک شروع میکنیم. از رگرسیون لجستیک برای حل مسائل دستهبندی استفاده میشود. این بدان معناست که متغیر هدف یا وابسته (یعنی همان متغیری که میخواهید آن را پیشبینی کنید)، از چند دسته یا طبقه تشکیل شده است. این دستهها میتوانند در قالب بله/ خیر یا عددی از 1 تا 10 (مثلاً بهعنوان میزان رضایت مشتری) باشند. مدل رگرسیون لجستیک با توجه به دادههای دریافتی، ابتدا از یک معادله برای ایجاد یک منحنی استفاده میکند و در مرحله بعد، همین منحنی را برای پیشبینی نتایج مشاهدات جدید به کار میگیرد.
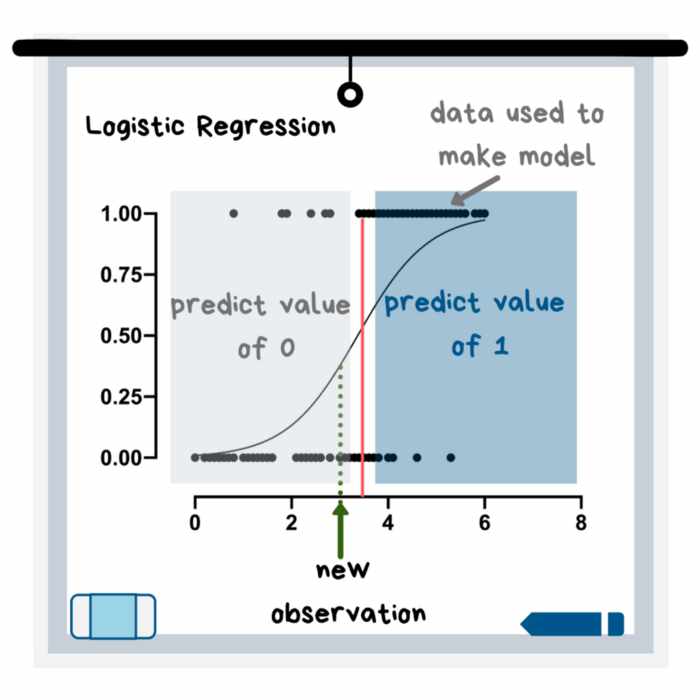
در نمودار بالا میبینیم که مشاهده یا داده جدید، بهواسطه قرار گرفتن در سمت چپ منحنی، مقدار پیشبینی “صفر” را اختیار کرده است. رگرسیون لجستیک با توجه به تعداد متغیرهای مستقل، به دو نوع ساده و چندگانه تقسیم میشود.
2. رگرسیون خطی
رگرسیون خطی معمولاً یکی از نخستین مدلهای یادگیری ماشین است که افراد به دلیل سادگی درک الگوریتم آن، بالأخص هنگام استفاده از یک متغیر x آن را میآموزند.
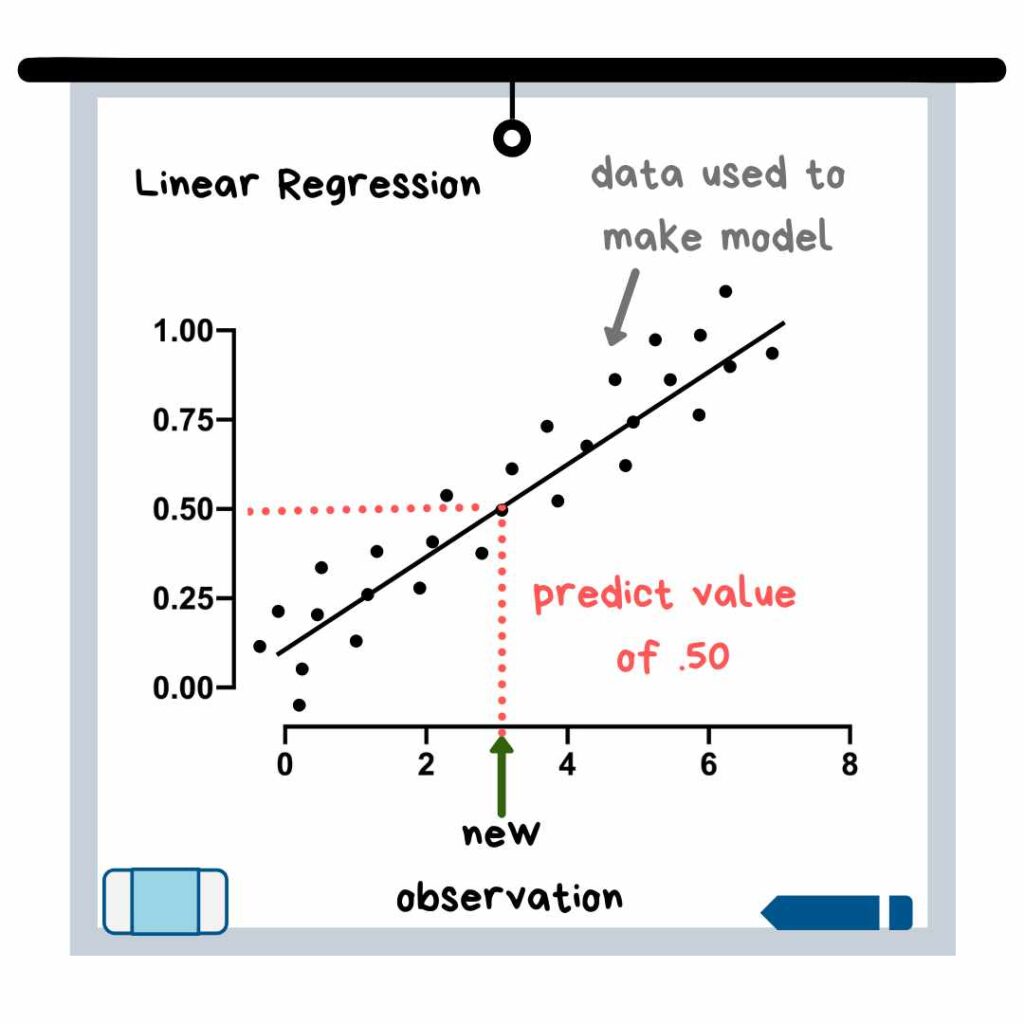
این مدلهای یادگیری ماشین بر مفهوم بهترین برازش خطی استوار هستند که از این خط برازش برای پیشبینی نقاط داده جدید استفاده میشود.
رگرسیون خطی تا حد زیادی به رگرسیون لجستیک شباهت دارد اما زمانی از آن استفاده میشود که متغیر هدف، از نوع پیوسته باشد؛ یعنی بتواند هر مقدار دلخواهی را اختیار کند. درواقع هر مدلی را با یک متغیر هدف پیوسته بهعنوان رگرسیون میشناسند. قیمت فروش خانه، مثالی از یک متغیر پیوسته است.
رگرسیون خطی، یکی از تفسیرپذیرترین مدلهای یادگیری ماشین است. در معادله مدل، برای هر متغیر، یک ضریب وجود دارد و این ضرایب نشان میدهند که به ازای هر تغییر کوچک در متغیر مستقل (متغیر x)، متغیر هدف یا وابسته چقدر تغییر میکند؟ اگر بخواهیم قیمت خانه را بهعنوان یک مثال در نظر بگیریم، با نگاه کردن به معادله رگرسیون درمییابیم که به ازای افزایش هر مترمربع (متغیر x)، قیمت فروش خانه مثلاً 10 میلیون تومان افزایش مییابد.
3. K– نزدیکترین همسایگی (KNN)
KNN یکی دیگر از مدلهای یادگیری ماشین تحت نظارت است که از آن میتوان هم برای دستهبندی و هم برای رگرسیون استفاده کرد. حرف K در نام این مدل، نشاندهنده تعداد نزدیکترین نقاط در فضای دادهای است؛ نقاطی که مدل باید آنها را برای تعیین مقدار پیشبینی بررسی کند. مقدار K را شما انتخاب میکنید و باید آنقدر با مقادیر بازی کنید تا ببینید کدام مقدار، بهترین پیشبینی را ارائه میدهد؟
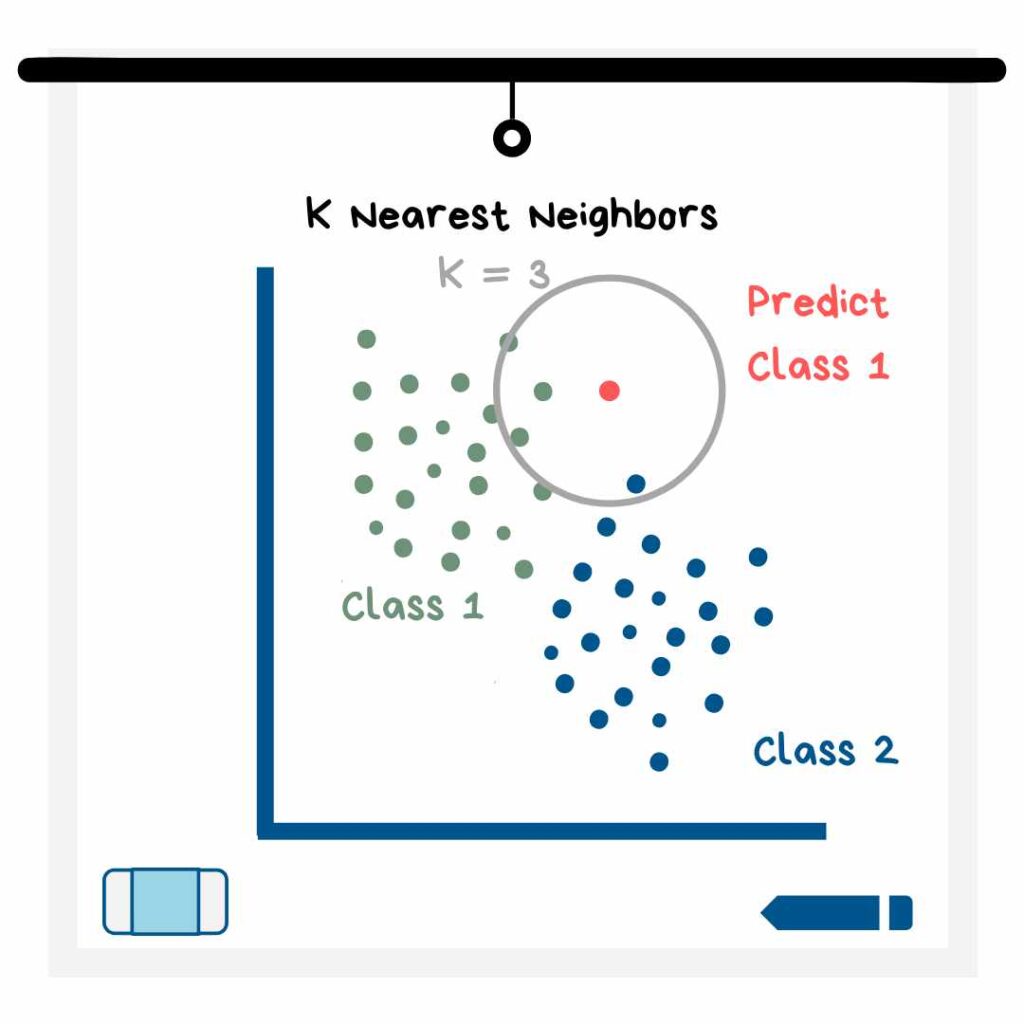
در شکل بالا، همه نقاط دادهای که در دایره K=3 قرارگرفتهاند، تعیین میکنند که مقدار متغیر هدف برای نقطه داده جدید چقدر باید باشد؟ هر مقداری از K که بیشترین امتیاز یا رأی را از نقاط مجاور کسب کند، همان مقداری است که مدل KNN آن را برای نقطه داده جدید، پیشبینی کرده است. همانطور که در شکل میبینیم، 2 تا از نزدیکترین نقاط قرار گرفته در دایره، متعلق به کلاس 1 بوده و یک نقطه به کلاس دو تعلق دارد. بنابراین مدل، برای نقطه داده جدید، کلاس 1 را پیشبینی میکند. اگر مدل بخواهد بهجای یک مقدار دستهای یا طبقهای، یک مقدار عددی را ارائه دهد، آنگاه تمام آرای نقاط همسایه، مقادیری عددی هستند که از میانگین آنها برای پیشبینی استفاده میشود.
4. ماشین بردار پشتیبان (SVM)
از دیگر مدلهای یادگیری ماشین، ماشین بردار پشتیبان است که در آن مرزی بین نقاط داده ایجاد میشود بهطوریکه اکثریت نقاط یک کلاس در یکسوی مرز و اکثریت نقاط کلاس دیگر در آنسوی مرز قرار میگیرند.
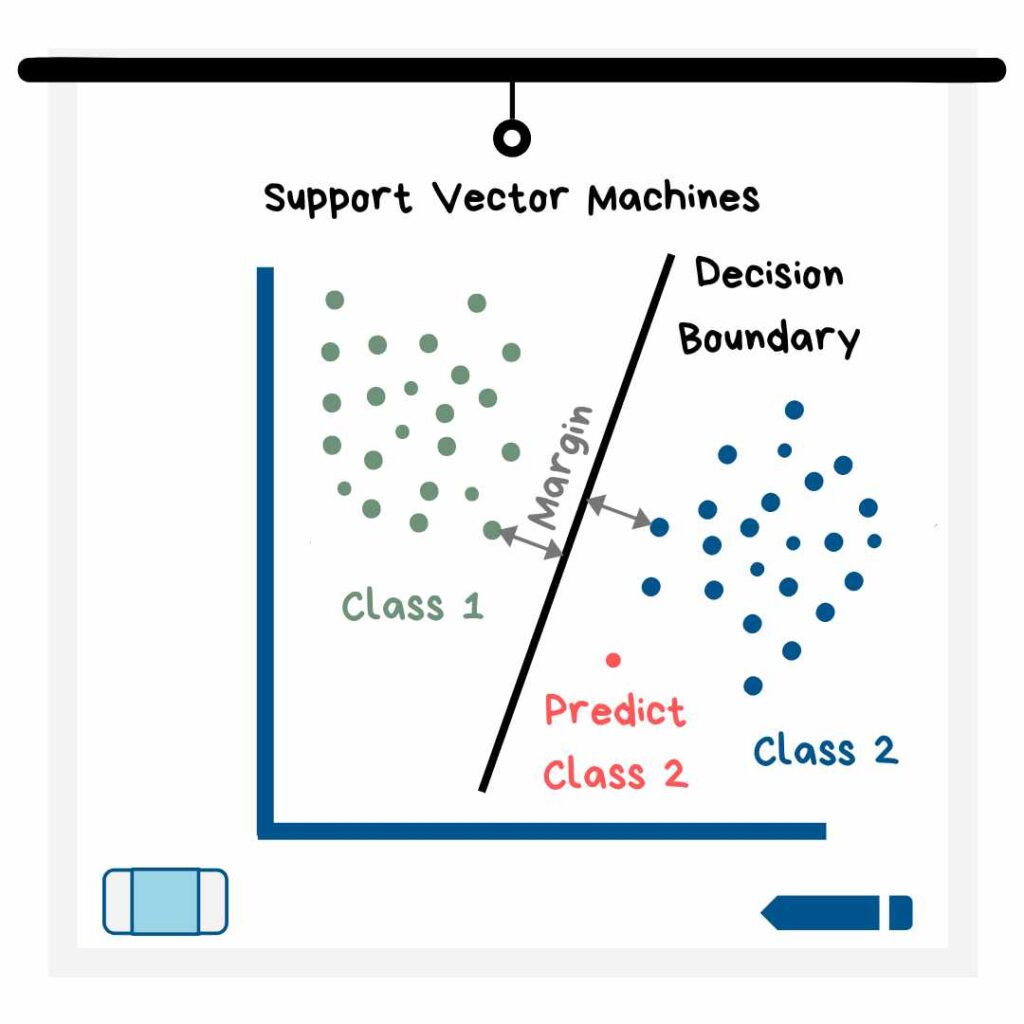
در اینجا هدف، یافتن مرز یا ابر صفحهای است که نسبت به هر دو دسته یا کلاس، حداکثر مقدار حاشیه را داشته باشد. در اینجا حاشیه، بهصورت فاصله بین نزدیکترین نقطه داده در هر کلاس تا ابر صفحه تعریف میشود. بعد از رسم ابر صفحه، نقاط داده با توجه به اینکه در کدام سمت آن قرار میگیرند، به کلاس 1 یا 2 منتسب میشوند. البته از این مدل علاوه بر دستهبندی، میتوان برای رگرسیون هم استفاده کرد.
5. درختهای تصمیمگیری و جنگلهای تصادفی
درختهای تصمیمگیری و جنگلهای تصادفی، نوع دیگری از مدلهای یادگیری ماشین بدون نظارت هستند که هم برای دستهبندی و هم رگرسیون میتوانیم از آنها استفاده کنیم. درختهای تصمیمگیری، جنگلهای تصادفی را ایجاد میکنند و هر درخت تصمیم، الگوریتمی برای طبقهبندی دادههاست؛ دادههایی که بین چند درخت تصمیم تقسیمشدهاند.
در این روش، پیشبینی و تصمیمگیری نه بر مبنای یک درخت، بلکه بر اساس مجموعهای از درختهای تصمیم یا همان جنگل تصادفی انجام میشود که در اغلب موارد، نتایج بهتری را در مقایسه با استفاده از یک درخت تصمیم ارائه میدهد.
مدلهای یادگیری ماشین بدون نظارت
حالا نوبت به معرفی مدلهای یادگیری ماشین بدون نظارت میرسد. یعنی مدلهایی که در آنها، دادهها برچسبگذاری نشده و کامپیوتر، بدون راهنمایی عامل انسانی، خودش روابط و الگوها را میشناسد. مدلهای یادگیری ماشین بدون نظارت، الگوریتمهای پیچیدهتری دارند که درک آنها دشوارتر است.
آنچه یادگیری بدون نظارت را به یک رویکرد ارزشمندتر تبدیل میکند این است که بهواسطه این نوع یادگیری، میتوانیم به الگوها و روابطی بین دادهها پی ببریم که شاید هیچوقت، احتمالی برای وجود این الگوها، قائل نمیشدیم.
1. خوشهبندی K میانگین (k-means clustering)
این مدلهای یادگیری ماشین با فرض وجود K خوشه در مجموعه دادهها کار را آغاز میکنند. ازآنجاییکه شما نمیدانید واقعاً چند گروه در دادههایتان وجود دارد، باید مقادیر مختلفی را برای K امتحان کنید و با توجه به معیارها و همینطور قدرت تفکر و تجسم، متوجه شوید کدام مقدار K میتواند منطقی باشد؟ روش K میانگین در خوشهبندیهای دایرهایِ هماندازه، نتایج بهتری ارائه میدهد.
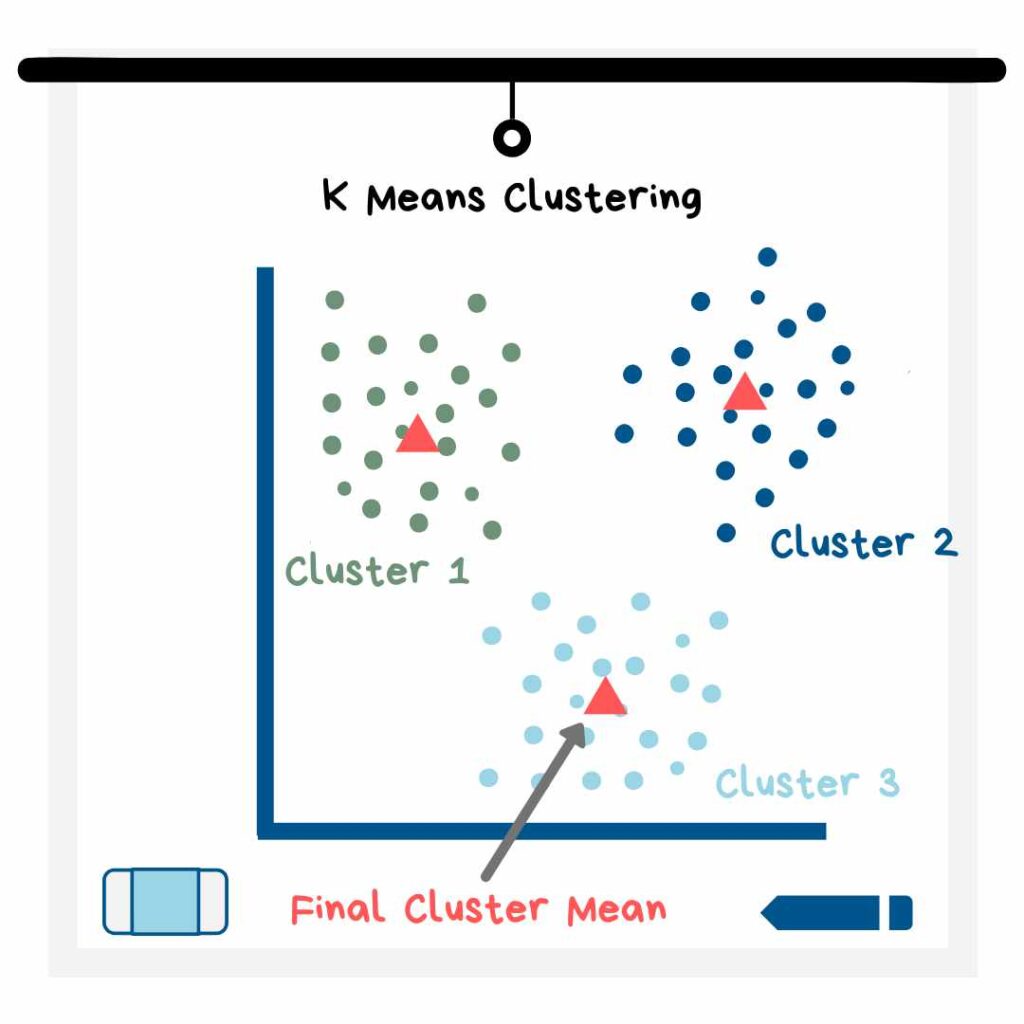
مدلهای یادگیری ماشین K میانگین، ابتدا بهترین نقطه داده را برای تشکیل مرکز هر یک از خوشه دادهها (که تعدادشان K است) انتخاب میکنند؛ بهترین داده مرکزی برای هر خوشه، نقطهای است که مجموع فاصله همه نقاط موجود در خوشه از آن، حداقل باشد. آنگاه برای هر نقطه، مراحل زیر تکرار میشوند:
- هر نقطه داده از کل دادهها، به خوشهای اختصاص مییابد که کمترین فاصله را با مرکز آن دارد. پس از اختصاص همه دادهها به خوشهها، آرایش جدیدی از خوشهها شکل میگیرد.
- مرکز خوشههای جدید از طریق محاسبه میانگین نقاط متعلق به همان خوشه مشخص میشود
2. الگوریتم خوشهبندی DBSCAN
مدلهای خوشهبندی DBSCAN از این نظر با مدلهای یادگیری ماشین K میانگین فرق دارند که در این روش نیازی به مقداردهی برای K نیست. ضمناً این مدل میتواند مرکز هر شکلی از خوشه (نه صرفاً خوشههای دایرهای) را پیدا کند. بهجای مشخص کردن تعداد خوشهها، شما باید حداقل تعداد دادههایی را که میخواهید در یک خوشه قرار بگیرند و همینطور شعاع اطراف هر نقطه داده را برای جستجوی خوشه، وارد کنید. بعدازاین مرحله، الگوریتم، خودش خوشهها را برایتان پیدا میکند. شما میتوانید مقادیر ارائهشده برای ساخت مدل را تغییر دهید تا به خوشههایی برسید که با توجه به منطق و معیار، مناسب باشند.
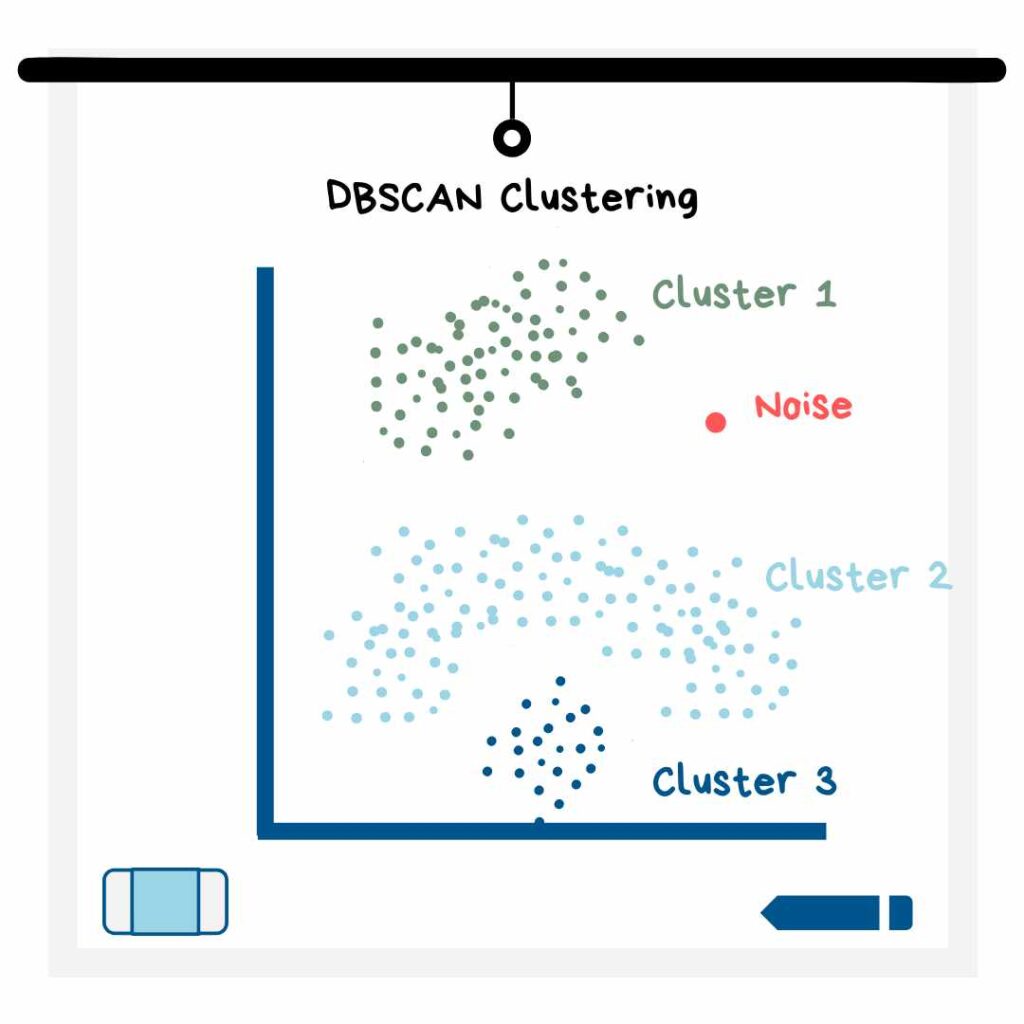
علاوه بر این، مدل DBSCAN نقاط نویز را نیز برای شما دستهبندی میکند. در اینجا نقاط نویز، به نقاطی گفته میشود که از سایر مشاهدات یا همان نقاط داده، دور هستند. این مدل، وقتیکه نقاط داده، فاصله بسیار کمی از یکدیگر داشته باشند، عملکرد بهتری در مقایسه با مدل خوشهبندی K میانگین دارد.
3.شبکههای عصبی
شبکههای عصبی را میتوانیم از جالبترین و درعینحال، رازآلودترین مدلهای یادگیری ماشین بدانیم. ازآنجاییکه این مدلها، سازوکاری شبیه به عملکرد سلولهای عصبی مغز انسان دارند، به این نام معروف شدهاند. این مدلها نیز با شیوه خاص خودشان، الگوها و روابط موجود در مجموعه دادهها را کشف میکنند. الگوریتم شبکههای عصبی گاهی الگوهایی را میشناسند که انسان هرگز قادر به کشف آنها نیست.

شبکههای عصبی بهخوبی از عهده کار با دادههای پیچیدهای مثل صدا و تصویر، برمیآیند. کاربرد این الگوریتمها را میتوانیم در بسیاری از قابلیتهای نرمافزاری جالب مثل سیستم تشخیص چهره یا دستهبندی متن که همه ما با آنها آشنا هستیم، مشاهده کنیم. از شبکههای عصبی میتوان هم برای کار با دادههای برچسبگذاری شده و هم دادههای بدون برچسب، استفاده کرد. بهعبارتدیگر، این الگوریتم در یادگیری ماشین، اعم از تحت نظارت و بدون نظارت، کاربرد گستردهای دارد. ازآنجاییکه باز کردن مبحث شبکههای عصبی، پیچیدگیهای بسیار زیادی دارد، در اینجا به ارائه همین توضیحات مختصر درباره این الگوریتم، بسنده میکنیم.
سخن آخر
در این مطلب تلاش کردیم مباحث کلی، مختصر و درعینحال مفیدی را درباره Machine Learning و همینطور مدلهای یادگیری ماشین خدمتتان ارائه دهیم. امیدواریم این مقاله در کنار ایجاد درک اولیه نسبت به این مفاهیم و ارتقای دانستههایتان درباره آنها، شما را به این نتیجه رسانده باشد که یادگیری ماشینی و مدلهای مختلف آن، چقدر مفید، کاربردی و البته جالب هستند.
یادگیری ماشین که نوعی هوش مصنوعی محسوب میشود، قابلیتهای حیرتانگیزی را در حل مسائل به انسان ارائه میدهد. گاهی باید کنار بایستیم و به کامپیوتر اجازه دهیم تا با سازوکارهای خودش، الگوها و روابط بین دادهها را پیدا کند. البته این سازوکار، میتواند گیجکننده باشد و جالب اینکه گاهی حتی خبرهترین متخصصان امر نیز نمیتوانند درک کنند که مدلهای یادگیری ماشین، دقیقاً با چه منطقی به یک نتیجه خاص میرسند؟ بااینحال، در اغلب اوقات همینکه بدانیم یادگیری ماشین به ما در پیشبینی کمک میکند، کافی و کارگشاست.
البته همیشه هم نمیتوان به چگونگی سازوکار یک کامپیوتر و شیوه استدلال آن در ارائه نتایج، بیاعتنا بود و گاهی درک منطق کامپیوتر، به مسئلهای حساس تبدیل میشود. مثلاً بعضی سازمانها در فرایند استخدام و ارزیابی داوطلبان شغلی، از هوش مصنوعی و یادگیری ماشین استفاده میکنند. واضح است که در چنین شرایطی، حصول اطمینان از درستیِ منطق کامپیوتر در ارزیابی داوطلبان و اینکه بدانیم این کار را چطور و بر اساس چه معیارهایی انجام میدهد، اهمیت بسیار زیادی دارد.
https://thenextweb.com/neural/2020/04/25/machine-learning-models-explained-to-a-five-year-old-syndication/